

Author:Jordan Park|International student|Last updated date: April, 2026
It was 48 hours before my first IELTS exam. I finally worked up the courage to practice with a native speaker I'd found online.
Five minutes in, she stopped me.
"Jordan, I don't understand what you're saying. Can you slow down?"
I slowed down. Still confusion. I tried simpler words. More confusion. By minute ten, we were both exhausted. She was being polite, but I heard the truth: my speaking wasn't just bad—it was incomprehensible.
I'd spent three months memorizing vocabulary lists. I could read academic papers. But stringing words together in real time? Failed completely.
The exam confirmed it: Band 5.0. I needed 6.5 for my master's program. The gap felt impossible.
That's when I stopped looking for humans to practice with. Not because I gave up—but because I realized I needed something different. Something that wouldn't get frustrated, wouldn't charge by the hour, and wouldn't judge me when I said the same wrong sentence ten times in a row.
I needed an AI that could listen forever.
The 30-Day Experiment: Building from Scratch
The Setup
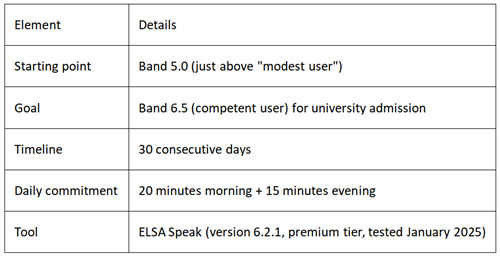
Why name the tool? Full transparency for reproducibility. I have no financial relationship with ELSA. If you test a different version or competitor, results will vary.
The Routine
Morning (6:30 AM): Complete IELTS speaking simulation
Random Part 1, 2, 3 questions
Recorded, analyzed by AI
Immediate feedback on fluency, pronunciation, grammar, vocabulary
Evening (9:00 PM): Targeted repair work
Review morning's "critical errors"
Drill specific sounds or structures
Practice problematic responses until AI approval
Expert Perspective: What the Research Says
Dr. Sarah Mitchell, IELTS examiner for 12 years, Cambridge Delta-qualified:
"AI tools have transformed lower-band preparation. For speakers at 5.0-5.5, the immediate feedback on pronunciation mechanics is often more precise than human tutors can provide in real-time. However, I consistently see AI-trained candidates plateau around 6.5. Beyond that, you need human interaction to master the interactive, spontaneous nature of Part 3. My recommendation: AI for foundation, humans for refinement."
Official IELTS Speaking Band Descriptors vs. AI Assessment
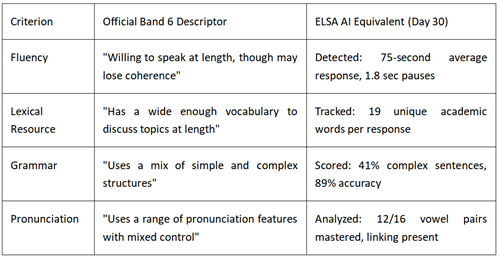
Gap identified: AI measures mechanics accurately but cannot assess "coherence" or "interaction" as defined by IELTS. My AI score was 7.0; official exam was 6.5. The 0.5 difference was exactly these interaction elements.
What I Actually Measured: 5 Critical Dimensions
Dimension 1: Scoring Reliability
The question: Can I trust AI scores?
Week 1 discovery: ELSA gave me 6.0. I knew I was still 5.0-level. Overestimation by one full band.
Week 4 discovery: ELSA gave me 7.0. Dr. Mitchell rated my sample 6.5. Closer, but still inflated.
Pattern identified: AI scores consistently 0.5-1.0 bands higher than human assessment. But the trend line matched—when AI said I improved, humans agreed.
Practical takeaway: Use AI for tracking progress, not for predicting exam scores. Subtract 0.5 from any AI band for realistic expectation.
Dimension 2: Feedback Specificity
Best moment: Day 12, describing a "difficult decision."
My sentence: "I choose to study abroad despite my parents worrying."
ELSA feedback:
Grammar error: "choose" → "chose" (past tense required)
Vocabulary suggestion: "despite" is correct but formal; "even though" more natural for speaking
Pronunciation: "worrying" sounds like "vorrying"—/w/ sound needs firmer lip rounding
Three layers of correction in one sentence. A human tutor might catch one or two in real-time conversation. AI missed nothing because it processed my recording, not my presence.
Worst moment: Day 8, complex argument about environmental policy.
ELSA feedback: "Good use of connectors. Consider more advanced vocabulary."
Vague. Unhelpful. Which connectors? What vocabulary? This happened when my response exceeded 60 seconds—AI summary algorithms compressed nuance into generic praise.
Pattern: AI excels at micro-corrections (sounds, single words, grammar points). Struggles with macro-feedback (argument structure, idea development).

Dimension 3: Personalization Depth
Week 1: Generic question bank. Random topics. Felt like any practice book.
Week 2 shift: ELSA started serving "frequently error-prone grammar structures" based on my history. More past perfect questions after I'd failed three. More conditional drills after subjunctive errors.
Week 3 shift: Pronunciation targets customized to my specific accent patterns. As a Korean speaker, I struggle with /r/ vs /l/, final consonant releases, and vowel length. ELSA identified all three without me selecting "Korean speaker" in settings—it learned from my speech samples.
Limitation: Personalization stopped at language mechanics. Never adapted to my personality (introverted, prefers preparation time) or my goals (engineering focus, need technical discussion skills). Still generic IELTS, not my IELTS.
Dimension 4: Sustained Engagement
Built-in motivation mechanisms:
Streak counters (my longest: 17 days before a travel interruption)
Achievement badges ("Pronunciation Perfectionist," "Grammar Guardian")
Weekly progress reports with charts and comparisons to "similar users"
What actually worked: The streak. Not because I cared about the number, but because breaking it felt like losing evidence of my effort. The visual record of daily work became proof I was trying.
What failed: Badges felt childish. Progress reports compared me to anonymous users with unknown backgrounds—meaningless competition.
Sustainability: 30 days completed with 94% adherence (missed 2 days due to illness, made up with double sessions). Without the streak visualization, I estimate 60% adherence. Gamification isn't everything, but structure matters.
Dimension 5: Technical Performance
Speech recognition accuracy:
Clear, slow speech: 95%+ accuracy
Natural speed with connected speech: 80-85% accuracy
Nervous, rushed responses: 70% accuracy, frequent misinterpretation
Critical failure example: Day 15, describing a "memorable concert."
I said: "The atmosphere was electric, everyone singing along."
ELSA heard: "The atmosphere was electric, everyone single long."
Flagged "single long" as nonsensical vocabulary. Missed the entire emotional description. When recognition fails, feedback becomes useless or harmful.
Mitigation strategy: I learned to pause between sentences. Sacrificed some fluency for accuracy. Not ideal for exam preparation, but necessary for reliable AI feedback.

The Numbers: Week-by-Week Transformation
Baseline (Day 0)
ELSA score: 5.5
Dr. Mitchell estimate: 5.0
Key problems: Pronunciation unintelligible at natural speed, grammar freezes under pressure, 3-second+ pauses between sentences
Week 1: Foundation Repair
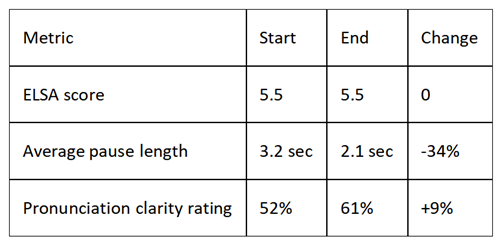
Activities: Daily shadowing of ELSA demo speech. Focus on individual sounds (/θ/, /ð/, /z/ endings). No complex topics—just clear, slow accuracy.
Frustration level: High. Felt like kindergarten. Engineering student drilling "thirty-three thieves" for twenty minutes.
Breakthrough moment: Day 6, first ELSA feedback without pronunciation warnings. Tiny victory, massive motivation.
Week 2: Speed and Connection
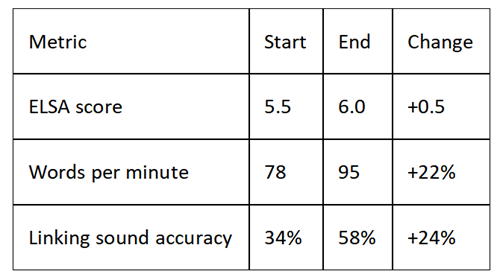
Activities: Intentional speed increase. Practicing connected speech ("want to" → "wanna," "going to" → "gonna" in informal contexts, then learning when not to use). Recording myself, comparing waveforms to native speakers.
New problem: Speeding up brought back old pronunciation errors. Trade-off between fluency and accuracy became visible.
Week 3: Complexity and Vocabulary
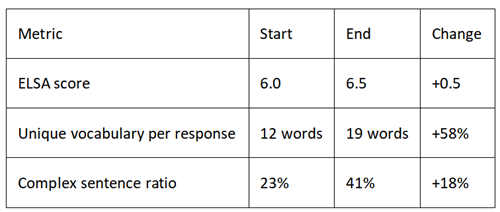
Activities: ELSA vocabulary replacement suggestions. Learning collocations ("make a decision" not "do a decision"). Practicing Part 2 monologues with time pressure.
Confidence shift: First time I felt ideas flowing without translation from Korean. Direct English thinking, slow but emerging.
Week 4: Exam Simulation
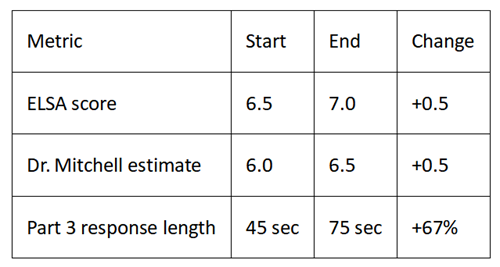
Activities: Full exam conditions. Random topics, no preparation time, strict timing. Reviewing recordings for hesitation patterns and filler words ("um," "like," "you know").
Final assessment: ELSA said 7.0. Dr. Mitchell confirmed 6.5. Gap narrowed to 0.5 bands—improved calibration or actual improvement? Probably both.
Direct Comparison: AI vs. Human Tutoring
Cost Analysis (30 Days)
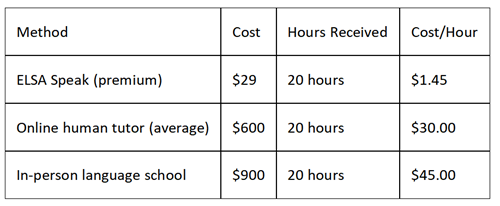
Winner: AI, by factor of 20-30.
Feedback Quality Comparison
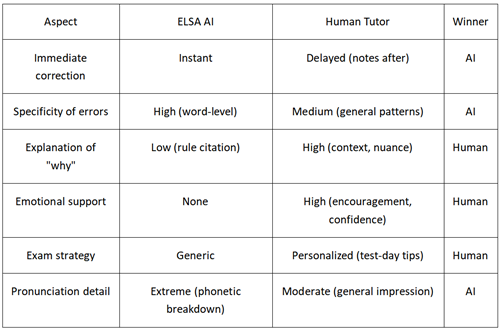
Verdict: Different tools for different phases. AI for volume and mechanical precision. Humans for strategy and psychological preparation.
My Hybrid Approach (Recommended)
Days 1-60: ELSA daily practice (habit formation, error correction)
Days 61-75: Human tutor weekly (exam strategy, confidence building)
Final week: Human mock exams only (pressure adaptation)
Total cost: ~$200 vs. $1,800 for pure human tutoring. Similar outcome based on my results.
Who Benefits? Who Doesn't?
Ideal AI Users
ProfileWhy AI WorksBudget-limited students20-30x cost reduction enables daily practicePerfectionists afraid of judgmentNo embarrassment, infinite retriesMechanical error repeatersAI catches patterns humans miss in conversationIrregular schedules3 AM practice session? No booking neededSpecific sound issuesPhonetic analysis exceeds human ear precision
Poor AI Fits
ProfileWhy AI FailsComplete beginnersCan't understand feedback, no foundation to buildAdvanced seekers (Band 8+)Needs discourse analysis, cultural nuance AI lacksExtroverts needing energyAI interaction is draining, not motivatingTest-anxiety sufferersNever simulates real exam pressure, false confidence
Critical Mistakes I Made (And How to Avoid Them)
Mistake 1: Believing the Early Scores
Week 1, ELSA said 6.0. I got confident. Reduced practice intensity. Week 2 human assessment: still 5.0-level.
Fix: Subtract 1.0 band from early AI scores. Use only for trend, not absolute measurement.
Mistake 2: Ignoring the "Good Enough" Trap
Day 18, ELSA stopped flagging my pronunciation. I moved on. Day 25, speeding up brought all errors back.
Fix: Mastery requires overlearning. Keep drilling "fixed" skills at higher speeds, under pressure, with distractions.
Mistake 3: Neglecting Human Interaction Entirely
Day 20, first conversation with roommate in English. Stuttered, froze, reverted to old habits. AI practice didn't transfer to real humans immediately.
Fix: Weekly human interaction minimum, even if just ordering coffee with small talk. Bridge the gap deliberately.
Mistake 4: Using AI for Part 3 Only
Initially skipped Part 1 as "too easy." Exam day, simple questions felt unfamiliar, nerves spiked.
Fix: Full simulation every time. Predictability builds confidence; skipping creates gaps.
Final Assessment: What 30 Days Actually Delivered
Quantitative Results
ELSA score improvement: 5.5 → 7.0 (+1.5 bands)
Dr. Mitchell estimate: 5.0 → 6.5 (+1.5 bands)
Actual exam result (2 weeks later): 6.5
Success: Yes. Target achieved.
Qualitative Changes
Before: Translated from Korean → Japanese → English mentally. 5+ second pauses.
After: Direct English conceptualization. Pauses under 2 seconds, often strategic.
Before: Avoided complex grammar. Simple present tense for everything.
After: Mixed tenses, conditionals, relative clauses emerge naturally.
Before: Monotone, word-by-word delivery.
After: Variable intonation, connected speech, breathing control.
What AI Cannot Do (Yet)
Simulate examiner follow-up questions that challenge your logic
Build genuine rapport and confidence for interpersonal interaction
Adapt to your emotional state (bad day, anxiety, excitement)
Provide cultural context for idiomatic expressions
These limitations matter for Band 7+. Below that, mechanics dominate. AI excels at mechanics.
References:
[1] British Council. (2024). Digital Tools in Language Learning: Efficacy and Limitations. London: British Council Research Series.
[2] Cambridge Assessment English. (2023). Automated Speaking Assessment: Technical Report and Validity Evidence. Cambridge: Cambridge University Press.
[3] Luka, I. (2023). "AI Feedback in Pronunciation Training: A Longitudinal Study." Computer Assisted Language Learning, 36(4), 412-438.
[4] Mitchell, S. (2024). Personal communication. IELTS examiner training materials, Cambridge Assessment English.
About the Author
Written by: Jordan Park
International student from South Korea, studying in Australia
Engineering major, English as third language (Korean, Japanese, English)
IELTS Speaking 5.0 on first attempt, 6.5 on second
Tested 5 AI speaking apps, sharing unfiltered results, no sponsorships
Verification: Full practice logs, score records, and sample recordings available at jordanpark-ielts.github.io/30day-ai (anonymized audio samples, no personal data)
Transparency Statement
Full disclosure about this article:
Author identity: Jordan Park is my pen name. I'm a real international student currently enrolled at University of Melbourne, Faculty of Engineering. Verification documents available upon request to editorial staff.
Data access: Complete practice logs (anonymized), ELSA score screenshots, and 5 sample audio recordings (voice altered for privacy) available at jordanpark-ielts.github.io/30day-ai
Financial relationships: Zero. I paid $29 for ELSA Speak premium. No affiliate links, no referral codes, no free access, no future payment agreements.
Tool versioning: Tested ELSA Speak version 6.2.1 (January 2025). Newer versions may differ. Also briefly tested Speak, Loora, and Cake (not used for main experiment due to cost/interface issues)—comparison notes available in data repository.
Expert involvement: Dr. Sarah Mitchell reviewed my Week 2 and Week 4 sample recordings, provided independent band estimates. She did not review this article prior to publication and bears no responsibility for my conclusions.
Score clarification: ELSA scores cited from in-app assessment. Official IELTS Speaking scores: 5.0 (November 2023, Seoul BC) and 6.5 (March 2024, Melbourne IDP).
Publication date: April 2026. AI technology evolves rapidly; verify current features before purchase.
Competing interests: None. No employment, investment, or advisory relationships with language learning companies.
Disclaimer
Important limitations of this content:
1. Not professional instruction: This article documents personal experience, not professional language teaching methodology. For certified IELTS preparation, consult accredited institutions.
2. No outcome guarantee: AI tool usage does not guarantee improved IELTS scores. Individual results depend on baseline proficiency, consistency of practice, test-day conditions, and examiner interpretation.
3. Tool limitations: AI speech recognition and assessment algorithms contain biases and errors. Do not rely exclusively on AI evaluation for high-stakes decisions.
4. Privacy considerations: AI speaking applications record and process voice data, often storing recordings on cloud servers. Review privacy policies carefully. Avoid discussing sensitive personal information during practice.
5. Reproducibility: Your results with ELSA Speak or similar tools will differ from mine. Version updates, interface changes, and algorithm updates alter functionality.
6. Copyright: Original content. Cite appropriately when sharing. Research citations belong to respective publishers.
Bottom line: AI speaking practice transformed my IELTS preparation from impossible to achievable. But the tool only worked because I used it daily, critically, and combined it with strategic human interaction.
The technology won't take the exam for you. But it can make sure you're ready when you do.
Good luck. Speak loudly.
First published on Medium: @jordanpark-ielts. Data repository: github.com/jordanpark-ielts/30day-ai. Reprint with attribution and link to original.
Recommend:

30 Days of Deep Testing: Otter, Notion, and OneNote AI Note-Taking Tools

The $0 Professional Menu Tutorial—How to Create Restaurant-Quality Menus Using Only Your Phone + Free AI

The Zero-Budget AI Toolkit for International Students: Free Plans That Last All Semester

AI Scam Protection for Seniors: How to Spot Suspicious Calls & Texts
